


工控机AI加速方案全解析:NPU_MXM_模块扩展,如何给你的工控机装上AI大脑
一、为什么你的工控机需要AI加速?
当产线质检、缺陷识别、视频分析等AI推理需求扑面而来,很多企业发现原有的工控机算力捉襟见肘——CPU通用计算跑AI模型效率低下,推理速度慢、功耗高,还占满CPU资源影响主控任务。AI加速扩展,正是解决这一痛点的关键技术路径。
本文聚焦三大主流AI加速方案——NPU加速模块、MXM显卡、模块化工控机,从原理、优劣势、适用场景到选型实操,帮你找到最适合的AI升级路径。
1.1 工控机AI加速的三条路径
目前工业场景中,给工控机增加AI算力的主流方案有三条:
- NPU加速模块:即插即用,以低功耗方式为工控机扩展AI推理能力,适合轻量推理场
- MXM显卡:利用工业级MXM接口显卡提供强劲GPU算力,适合视觉检测等高算力需求
- 模块化工控机:在新购设备阶段,选择CPU+GPU原生集成的模块化架构,一步到位
二、三大AI加速方案横向对比
2.1 NPU加速模块
NPU(神经网络处理器)是专为AI推理设计的专用芯片,集成在 PCIe / M.2 / eGPU 等接口的加速模块上,通过即插即用的方式为工控机注入AI算力。
核心优势:
- 即插即用:5分钟扩展AI能力,无需整机更换
- 低功耗(5~25W):对工控机电源和散热压力小
- 框架支持完善:TensorFlow、PyTorch、ONNX Runtime均可部署
- 成本适中:800~3K元/卡,适合批量部署
主要局限:
- 算力上限约5~16 TOPS,不适合大模型推理
- 依赖CPU平台兼容,需确认接口和驱动支持
2.2 MXM显卡扩展
MXM(Mobile PCI Express Module)是一种标准化的笔记本/工业级显卡模块接口,比普通PCIe显卡更紧凑、功耗更可控,适合对空间和可靠性有要求的工业场景。
核心优势:
- 算力强:30~275 TOPS,覆盖从视觉检测到大模型推理
- CUDA生态成熟:直接使用NVIDIA驱动和工具链,迁移成本低
- 工业级MXM卡可靠耐用,支持宽温运行
主要局限:
- 功耗较高(35~250W),需匹配工控机电源和散热设计
- 价格区间较大:3K~15K元,需综合评估性价比
2.3 模块化工控机
模块化工控机将AI算力模块(CPU+GPU/NPU)作为可拆卸的功能模块集成到底盘上,在出厂阶段完成CPU与GPU的深度协同设计,是工业场景中AI能力最强、可靠性最高的方案。
核心优势:
- CPU+GPU原生设计:硬件协同优化,AI推理效率更高
- 宽温宽压设计:适应-40C~85C严苛环境,IP防护完善
- 可按需选配算力模块,灵活升级
- 长生命周期供货保障:7~10年稳定供应,避免中途停产风险
主要局限:
• 需整机采购,初期成本较高(8K~40K元)
• 算力升级需更换整机模块,灵活性略低
三、NPU加速模块生态详解
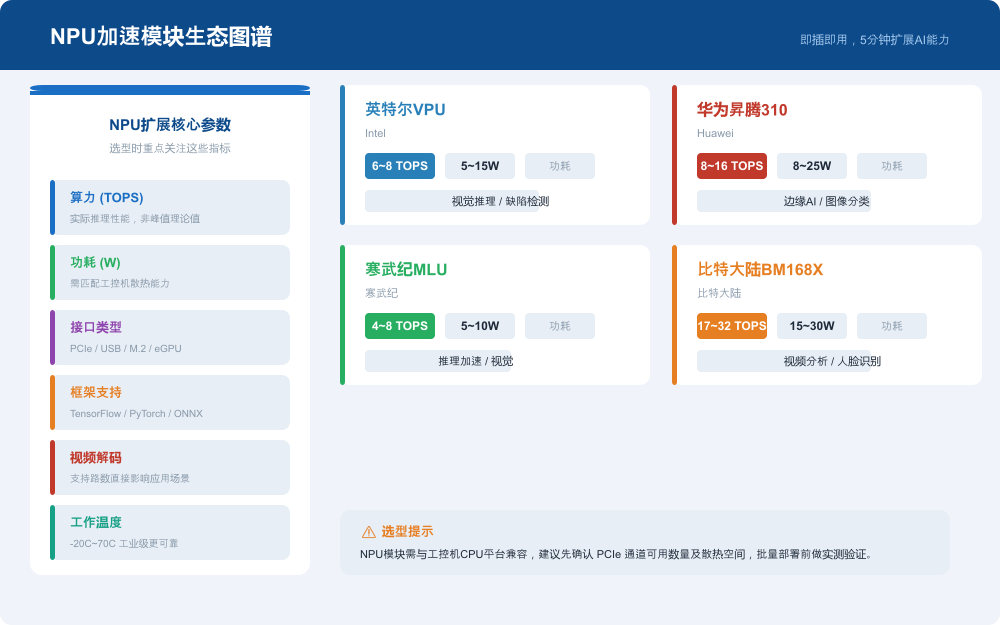
3.1 主流NPU产品一览
工业场景常用的NPU加速模块按生态和性能可分为四大阵营:
|
产品系列 |
代表厂商 |
算力 (TOPS) |
功耗 (W) |
典型应用场景 |
|
英特尔VPU |
Intel |
6~8 |
5~15 |
视觉推理 / 缺陷检测 |
|
昇腾310 |
华为 |
8~16 |
8~25 |
边缘AI / 图像分类 |
|
寒武纪MLU |
寒武纪 |
4~8 |
5~10 |
推理加速 / 视觉 |
|
比特大陆BM168X |
比特大陆 |
17~32 |
15~30 |
视频分析 / 人脸识别 |
3.2 NPU选型六大关键参数
选型NPU模块时,以下六个参数是决定最终AI推理效果的核心变量,必须逐一核实:
- 实际算力(TOPS):注意区分峰值算力与实际推理性能,部分厂商以峰值标注
- 功耗(W):需与工控机电源额定功率和散热能力匹配
- 接口类型:PCIe / USB / M.2 / eGPU,确认工控机空闲槽位
- 框架支持:TensorFlow / PyTorch / ONNX Runtime,关系到模型迁移工作量
- 视频解码能力:支持路数直接决定可覆盖的视频分析场景规模
- 工作温度范围:工业级-20C~70C比消费级0C~45C更可靠
四、场景化选型指南
4.1 轻量推理场景:数据采集与简单分类
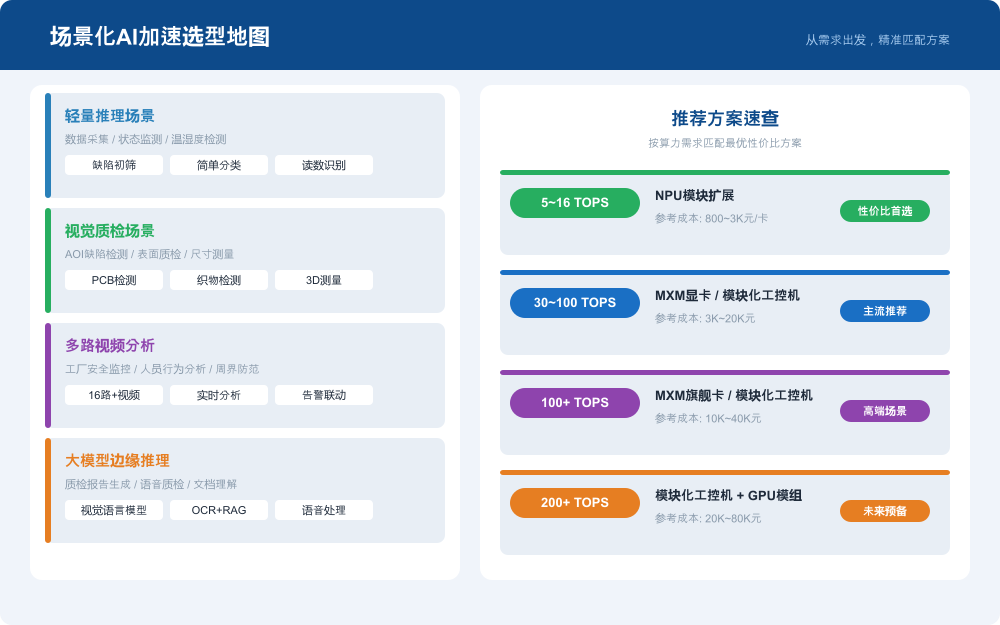
缺陷初筛、读数识别、简单分类等轻量AI任务,算力需求约5~16 TOPS,推荐NPU模块扩展。
推荐方案:NPU加速模块(800~3K元/卡)
- 已有工控机:直接插入空闲PCIe/M.2槽位,5分钟完成部署
- 部署成本低,适合批量产线快速铺开
- 功耗仅5~25W,对产线电力改造要求低
4.2 视觉质检场景:缺陷检测与AOI
PCB检测、织物表面质检、3D尺寸测量等场景,算力需求约30~100 TOPS,推荐MXM显卡或模块化工控机。
推荐方案:MXM显卡(3K~20K元)
- 单卡30~100 TOPS算力,可实时处理产线高清相机数据流
- 工业级MXM卡支持7x24小时连续运行,MTBF > 50000小时
- CUDA生态成熟,YOLO、ResNet等视觉模型迁移便捷
4.3 多路视频分析:工厂安全与人员行为
16路以上实时视频分析、人脸识别、周界防范等场景,算力需求100+ TOPS,推荐MXM旗舰卡或模块化工控机。
推荐方案:MXM旗舰卡 / 模块化工控机(10K~40K元)
• 需同时处理多路1080P/4K视频流,需强算力+大显存
• 模块化工控机在宽温、抗振动方面更适配工厂环境
4.4 大模型边缘推理:视觉语言模型与RAG
质检报告自动生成、OCR+RAG文档理解、多模态AI质检等前沿场景,算力需求200+ TOPS,推荐模块化工控机+GPU扩展方案。
推荐方案:模块化工控机 + GPU模组(20K~80K元)
• 视觉语言模型(VLM)边缘部署需要大算力+大显存组合
• 模块化工控机原生设计确保CPU与GPU高效协同,减少通信瓶颈
• 长生命周期供货保障,避免大模型快速迭代带来的硬件过时风险
五、选型决策实战:从需求到落地的五步法
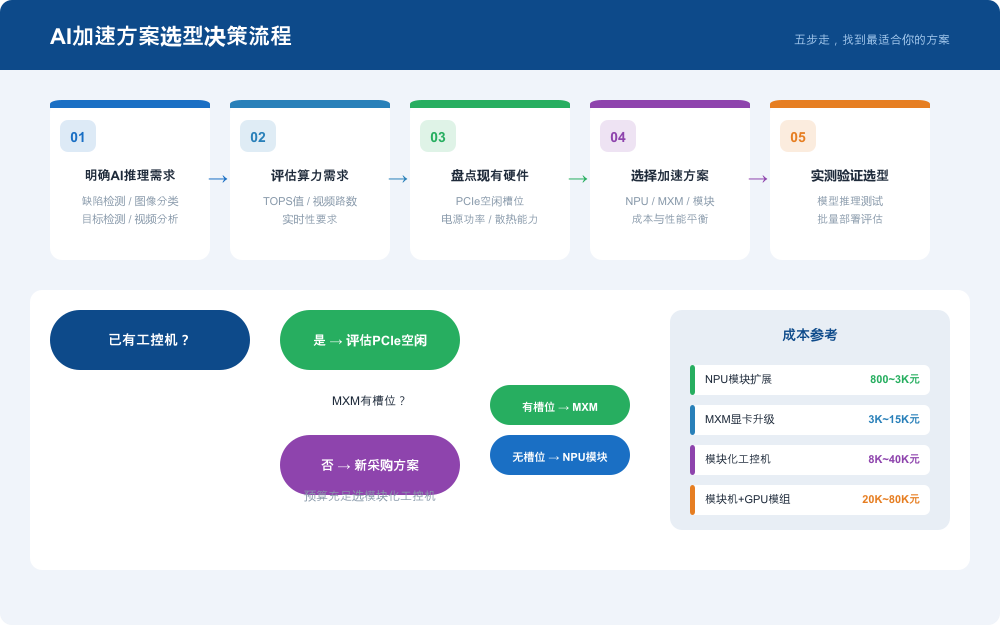
第一步:明确AI推理需求
这是整个选型的起点。需要回答:缺陷检测还是图像分类?实时性要求多高?是否需要多路视频同步处理?需求越具体,后续选型越精准。
第二步:评估算力需求
将AI模型推理需求转化为TOPS数值。注意区分峰值算力与实际可用算力——实际推理性能通常为峰值TOPS的30%~60%,建议以实测值为准。
第三步:盘点现有硬件资源
已有工控机的PCIe空闲槽位数量、电源额定功率、机箱散热能力,直接决定可扩展的加速方案。若电源仅剩200W余量,MXM旗舰卡(250W)就无法直接使用。
第四步:选择加速方案
根据前三步结果,结合成本预算,选定NPU模块 / MXM显卡 / 模块化工控机三者之一,或组合方案。参考原则:
- 已有工控机 + PCIe有槽位 + 预算有限 -> NPU模块
- 已有工控机 + MXM有槽位 + 算力需求高 -> MXM显卡
- 新采购 + 严苛环境 + 高可靠 -> 模块化工控机一步到位
第五步:实测验证选型
在正式批量部署前,用真实模型和真实数据进行推理测试,关注帧率、延迟、功耗、散热四大指标,确认方案满足需求后再推进。
六、总结与建议
AI加速不是一道单选题,而是根据企业现状(已有设备、预算、场景需求)动态求解的适配题。
已有工控机,优先评估NPU模块扩展:成本低、部署快、风险小
算力需求高且有PCIe/MXM扩展条件,MXM显卡性价比突出
新采购设备或严苛工业环境,模块化工控机是最稳妥的长期选择
大模型推理需求,2026年可重点关注国产AI模块化工控机的成熟度提升





售前电话:4008-616-216售前邮箱:sales@hwsys.cn
售后电话:4008-616-216售后邮箱:support@hwsys.cn
- 产品服务模块化工控机嵌入式工控机服务器/工作站标准主板AI人工智能计算模组工业平板电脑软件系统定制服务
- 解决方案矿山电力交通石化轨交储能水务机器人智能制造粮库
- 服务与支持资料下载维修申请问题反馈
- 关于汉为公司介绍发展历程企业荣誉技术创新核心优势合作伙伴联系我们