


AI工控机+大模型:边缘侧部署开源大模型的实战指南
当DeepSeek、Llama、Qwen等开源大模型席卷AI行业,一个关键问题浮出水面:这些动辄几十亿参数的模型,能否跑在工业现场的工控机上?答案是肯定的——通过模型量化、知识蒸馏、边缘推理引擎等技术,大模型正在从云端"下沉"到产线,在AI工控机上实现本地化部署与实时推理。本文将系统解析大模型边缘部署的技术路径、硬件选型、量化策略与落地场景,帮助企业找到"算力下沉"的最优解。
一、大模型为什么需要"跑到工控机上"?
大模型的云端部署模式在消费级应用中已相当成熟,但在工业场景中,将所有数据上传云端推理面临三大痛点:
1. 延迟不可控:网络往返延迟50-200ms,对于产线实时质检、设备故障预警等场景,延迟每多一毫秒都可能意味着产线停机。
2. 数据安全红线:电力、医疗、军工等行业的数据安全法规要求"数据不出园区",全量上传云端存在合规风险。
3. 网络不可靠:矿山、远洋、野外等场景网络不稳定,断网即停机的云端方案无法保障业务连续性。
AI工控机作为工业现场的算力中枢,具备高性能计算、宽温运行、工业级可靠性等特性,天然是大模型边缘部署的最佳载体。将大模型跑在工控机上,既能享受本地推理的低延迟与数据安全,又能通过云边协同实现模型持续迭代。
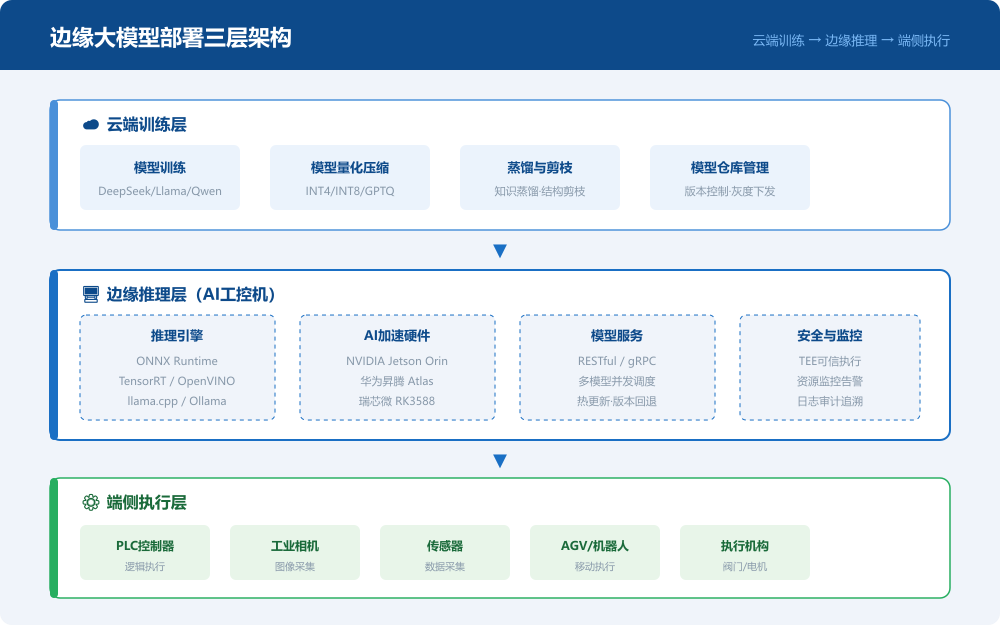
二、大模型边缘部署的核心技术路径
2.1 模型量化:从FP16到INT4的压缩魔法
模型量化是大模型边缘部署的第一步,也是影响最大的技术手段。通过降低模型参数的数值精度(从FP16浮点数压缩到INT8甚至INT4整数),可以在精度损失可控的前提下,将模型体积压缩2-4倍,推理速度提升2-5倍。
|
量化方式 |
模型体积(7B) |
推理精度 |
推理速度 |
适配算力平台 |
|
FP16 |
14GB |
★★★★★ |
★★☆☆☆ |
GPU 32GB+ |
|
INT8 |
7GB |
★★★★☆ |
★★★★☆ |
Jetson Orin / RTX 4090 |
|
INT4/GPTQ |
3.5GB |
★★★☆☆ |
★★★★★ |
Jetson / 昇腾310 / RK3588 |
关键结论:对于大多数工业场景的文本理解、报告生成任务,INT4量化已能满足精度要求;对于精度敏感的故障诊断、安全评估场景,建议使用INT8量化以保留更多模型能力。
2.2 推理引擎:工控机上的"模型运行时"
量化后的模型需要通过推理引擎加载运行。当前主流的边缘推理引擎包括:
- llama.cpp / Ollama:轻量级CPU+GPU混合推理框架,支持GGUF格式量化模型,是当前社区最活跃的边缘部署方案。Ollama在llama.cpp基础上封装了一键部署、模型管理等能力,大幅降低了部署门槛。
- ONNX Runtime:微软开源的跨平台推理引擎,支持CPU/GPU/NPU多后端,兼容性强,适合需要跨硬件平台部署的场景。
- NVIDIA TensorRT:NVIDIA GPU专用推理加速引擎,在Jetson平台上可获得最优推理性能,但仅限NVIDIA生态。
- Intel OpenVINO:Intel CPU/iGPU/VPU专用优化引擎,适合采用Intel处理器的工控机平台,在CPU推理场景下性能优异。
2.3 知识蒸馏与模型剪枝:让大模型"瘦身"到底
除量化外,知识蒸馏和模型剪枝是进一步压缩模型的两大利器。知识蒸馏将大模型(教师模型)的知识迁移到小模型(学生模型)中,如将70B模型的推理能力蒸馏到7B甚至3B模型;模型剪枝则直接移除模型中对输出影响较小的参数,减少计算量。两种技术可叠加使用,配合INT4量化,可将70B模型压缩至仅2-3GB,在算力有限的嵌入式工控机上也能运行。
三、AI工控机的硬件选型指南
大模型对算力的需求远超传统工控应用,选型时需重点关注以下几个维度:
3.1 AI算力:TOPS不是唯一指标
AI算力通常以TOPS(每秒万亿次运算)衡量,但TOPS数值并不能完全代表大模型推理的实际性能。需综合考量:
- 内存带宽:大模型推理是典型的"内存带宽瓶颈"型任务,推理速度往往受限于内存带宽而非纯算力。Jetson Orin的内存带宽(204.8GB/s)远优于同价位GPU。
- 可用内存:7B模型INT4量化后需要约4-5GB可用内存(含推理开销),选型时必须确保工控机内存容量充足,建议预留30%余量。
- AI加速单元:NPU/GPU的INT8/INT4推理效率是关键。瑞芯微RK3588的6 TOPS NPU实际推理效率优于同等TOPS数值的通用GPU。
3.2 三级算力推荐方案
|
级别 |
代表硬件 |
AI算力 |
适配模型 |
典型应用 |
|
入门级 |
RK3588 / RK3576 |
6 TOPS |
1-3B INT4 |
文本分类·意图识别 |
|
主流级 |
Jetson Orin NX / 昇腾310 |
70-100 TOPS |
7-14B INT4 |
智能问答·报告生成 |
|
旗舰级 |
Jetson AGX Orin / 昇腾910 |
200-640 TOPS |
32-70B INT8 |
多模态推理·代码生成 |
3.3 全国产化方案:飞腾+昇腾+麒麟已跑通7B
对于电力、政务、军工等对国产化有明确要求的行业,全国产工控机方案已具备部署7B模型的能力。飞腾D3000系列CPU提供8核高性能计算能力,华为昇腾Atlas 200/300加速模块提供8-70 TOPS的AI算力,银河麒麟V10操作系统已适配llama.cpp、ONNX Runtime等主流推理框架。实测数据显示,飞腾+昇腾方案在7B模型INT8量化下,推理速度可达8-12 tokens/s,满足大部分工业文本理解与生成场景的实时性要求。
四、五大典型落地场景
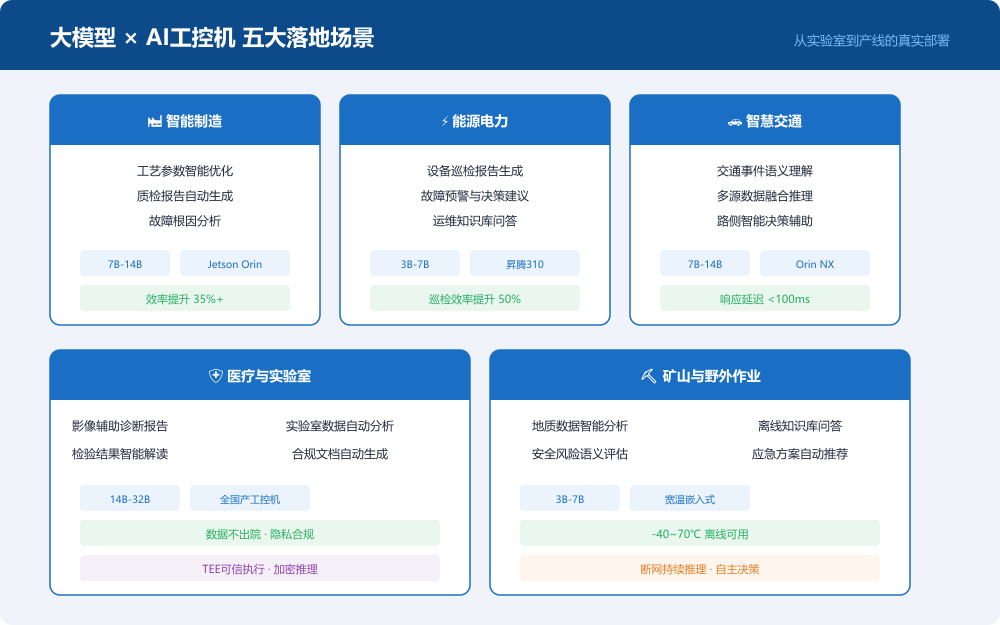
4.1 智能制造:工艺参数优化与质检报告生成
在电子制造、汽车零部件等产线中,部署7B-14B模型的AI工控机可实时分析工艺参数偏差,自动生成质检报告与改进建议。相比传统规则引擎,大模型能理解非结构化的工艺文档、历史故障记录,给出更精准的参数调整建议。某汽车零部件工厂实测数据显示,大模型辅助的工艺优化使产线良品率提升3.2%,质检报告生成效率提升35%。
4.2 能源电力:设备巡检报告与运维知识库问答
光伏电站、风电场的设备巡检涉及大量文本记录与图片数据。部署3B-7B模型的AI工控机可自动将巡检数据转化为结构化报告,并基于本地运维知识库回答工程师的现场提问。全国产工控机方案(飞腾+昇腾+银河麒麟)确保电力数据不出站,满足等保合规要求。某省级电网试点显示,AI辅助巡检使报告生成效率提升50%,故障识别准确率达96.7%。
4.3 智慧交通:交通事件语义理解与路侧决策辅助
在车路协同(V2X)场景中,路侧AI工控机部署7B-14B模型,可对多传感器融合感知结果进行语义理解,如识别"前方施工导致车道变窄"等复杂事件描述,并生成调度建议。边缘本地推理确保100ms内完成感知-理解-决策闭环,满足智能交通的实时性要求。
4.4 医疗与实验室:辅助诊断与合规文档生成
医疗行业对数据隐私要求极高,"数据不出院"是底线。部署14B-32B模型的全国产工控机(TEE可信执行环境+硬件加密)可在院内完成影像辅助诊断、检验报告智能解读、合规文档自动生成等任务。某三甲医院试点显示,AI辅助诊断使影像报告初稿生成时间缩短60%,且所有推理过程均在院内完成,零数据外泄。
4.5 矿山与野外作业:离线知识库与应急方案推荐
矿山、油田、远洋等场景网络不稳定甚至完全断网。部署3B-7B模型的宽温嵌入式工控机(-40~70℃工作温度)可将行业知识库"搬"到现场,实现离线问答、地质数据智能分析、安全风险语义评估、应急方案自动推荐等能力。断网持续推理、自主决策的特性,确保极端工况下的业务连续性。
五、部署实战:六步落地指南
- 明确模型需求:确定任务类型(NLP/CV/多模态)、模型规模(1B/7B/14B/70B)、延迟容忍度。工业文本理解类任务推荐7B-14B模型,简单分类任务1-3B即可。
- 算力预算评估:根据模型规模和量化方案计算所需TOPS、内存容量、功耗预算。7B模型INT4量化建议≥8GB可用内存,14B模型建议≥16GB。
- 量化方案选型:对精度敏感场景用INT8,延迟敏感场景可尝试INT4/GPTQ。建议先INT8验证功能,再根据性能需求决定是否降精度。
- 环境适配验证:确认工作温度范围、防护等级、EMC认证是否满足现场要求。户外部署必须选宽温+高防护等级。
- 软件栈部署:选择推理框架(Ollama/ONNX Runtime/TensorRT),完成模型加载、API服务化封装、监控告警配置。推荐Ollama一键部署方案降低运维门槛。
- 灰度上线验证:小规模部署压测→精度回归测试→全量推广。重点关注长时运行稳定性(72h+持续推理)、温度监控、内存泄漏检测。
六、未来趋势:端侧智能的三个方向
- 端侧小模型持续进化:DeepSeek、Qwen等开源模型持续推出更小参数量的蒸馏版本(1.5B、0.5B),推理成本进一步降低,嵌入式工控机也将具备大模型能力。
- 多模态边缘推理:视觉-语言模型(VLM)的边缘化部署是下一个爆发点,AI工控机将同时具备"看"和"想"的能力,为工业视觉质检带来质变。
- 国产算力生态成熟:飞腾+昇腾+麒麟的全国产化方案正在从"能用"走向"好用",推理框架适配日趋完善,国产工控机跑大模型将成为信创领域的标配能力。
结语
大模型从云端走向边缘,是AI赋能工业的必然趋势。AI工控机凭借工业级可靠性、宽温运行、本地推理等特性,成为大模型边缘部署的最佳载体。通过模型量化、推理引擎优化、云边协同架构,企业完全可以在工业现场跑通开源大模型,实现数据不出园、延迟可控、离线可用的智能升级。
无论您是正在探索AI+制造的产线工程师,还是规划边缘智能架构的系统集成商,AI工控机+大模型这条路径都值得认真评估。选择合适的硬件平台、量化方案和推理框架,大模型距离您的产线,可能只差一台工控机。





售前电话:4008-616-216售前邮箱:sales@hwsys.cn
售后电话:4008-616-216售后邮箱:support@hwsys.cn
- 产品服务模块化工控机嵌入式工控机服务器/工作站标准主板AI人工智能计算模组工业平板电脑软件系统定制服务
- 解决方案矿山电力交通石化轨交储能水务机器人智能制造粮库
- 服务与支持资料下载维修申请问题反馈
- 关于汉为公司介绍发展历程企业荣誉技术创新核心优势合作伙伴联系我们